DITA
Définition
DITA (pour Darwin Information Typing Architecture) est un standard XML OASIS (créé originellement par IBM) dont les spécifications définissent des types d'objets pour la rédaction et l'organisation d'une information structurée orientée sujet (Topic oriented), c'est à dire basée sur des fragments de contenus autonomes et réutilisables permettant d'améliorer la production, la cohérence et la maintenabilité de l'information.
Standard XML public depuis 2001, la spécification DITA est en version 1.2 depuis décembre 2010. Cette version introduit notamment des objets permettant la création de contenu pédagogique (learning and training elements).
Contexte
De part son historique, ses caractéristiques et ses fonctionnalités, DITA est un standard adapté à la documentation technique et dont l'utilisation est a priori répandue dans les entreprises ayant un fort besoin en documentation technique, et ce notamment dans les pays anglo-saxons. (cf. liste d'entreprises utilisant DITA, recensées récemment dans un blog américain dédié à la rédaction technique avec DITA).
Il existe de nombreux sites dédiés à DITA sur Internet :http://dita.xml.org/, http://www.ditausers.org/, http://www.ditainfocenter.com/, http://www.ditawriter.com/, etc.
Pour répondre à ce besoin, de nombreux éditeurs XML et outils de gestion de contenu structurés (CCMS[1]) du marché offrent ainsi une compatibilité plus ou moins complète avec ce standard et fournissent les outils pour gérer un tel contenu.
C'est la raison pour laquelle nous avons étudié ce standard dans le cadre du démonstrateur Graphène, afin d'en analyser les avantages et les inconvénients pour concevoir un produit le mieux adapté possible à la production de documentation technique (et assurant si possible une compatibilité avec cette norme).
Avantages
DITA offre un modèle normé, qui permet aux rédacteurs de rédiger du contenu de façon structuré, en fragments autonomes typés - les Topic - et agençables de manière arborescente dans une structure - la Map - permettant la publication.
Un principe de spécialisation permet de créer des objets propres aux besoins métiers, en héritant des objets proposés comme base au modèle : Concept, Task, Reference, eux même héritant de l'objet Topic. Cette spécialisation permet aux organisations de créer leur propre modèle documentaire, dont les objets métier et le vocabulaire sont ainsi adaptés à leur besoin. De plus, le mécanisme de spécialisation DITA basé sur le principe d'héritage assure l'interopérabilité de tout contenu DITA.
Un moteur de publication permet de publier du contenu DITA sous différents formats (PDF, HTML, JavaHelp, etc.) : DITA Open Toolkit (DITA OT).
DITA OT est un projet open source soutenu par plusieurs grandes sociétés qui contribuent directement à son développement (IBM, Adobe Systems, Astoria, OASIS, COMTech, etc.). DITA OT permet de publier tout contenu DITA, standard (Map, Topic, Taks, Concept, Reference) ou spécialisé. Dans le cas d'une spécialisation, la publication standard fonctionnera, mais sera bien entendue dégradée pour les contenus spécialisés (dont les spécificités ne sont pas connues par le moteur de publication). Il est donc possible d'adapter DITA OT afin d'implémenter la publication des spécialisations du modèle et de modifier le rendu graphique des publications.
La version actuelle de DITA OT est la 1.5.4.
Le standard DITA, tout comme le projet DITA OT, évolue régulièrement pour apporter de nouveaux éléments à la structure et de nouvelles fonctionnalités.
Fonctionnalités
Voici les fonctionnalités principales de la DITA :
rédaction fragmentaire Topic oriented pour optimiser la production, le suivi et la maintenance du contenu ;
agencement et réutilisation des fragments en Map pour une publication contextualisée et multi-support ;
spécialisation permettant l'adaptation du standard au métier ;
utilisation de références pour lier les fragments entre eux : lien xref pour faire une référence vers un autre fragment de contenu, et lien conref pour faire une référence pointant vers n'importe quelle partie à l'intérieur d'un fragment de contenu ;
l'inclusion de contenu (avec l’utilisation de la balise conref, permettant de pointer (pull) tout élément de contenu d'un fragment) pour faciliter le single sourcing (l'information n'est qu'à un seul endroit mais peut être utilisée à plusieurs endroits) ;
insertion d'image, d'imageMap (image zonée sur le principe de l'imagemap HTML) et de tableaux pour réaliser des contenus riches ;
publication conditionnelle, via l'utilisation d'attributs standard DITA (notamment platform, product, audience) et le paramétrage du fichier ditaval de DITA OT, pour filtrer le contenu à la publication et influer sur quelques paramètres de rendu ;
le chunking, via le paramétrage d'attributs de l'objet Map, permettant la fragmentation ou l'inclusion "des pages" du contenu au moment de la publication afin d'ajuster la granularité des pages HTML lors de la publication.
L'héritage et la spécialisation
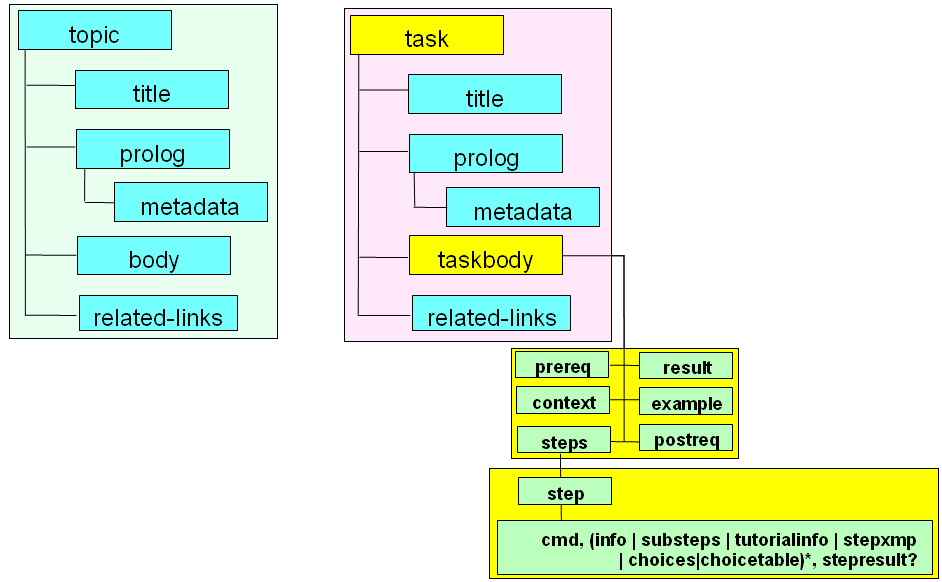
Ce schéma représente de façon simplifiée la spécialisation de l'objet Task issu de l'objet Topic : le body du Topic est remplacé par un Taskbody qui a été spécialisé afin de répondre au besoin de représentation d'un contenu de type Procédure. Les objets utilisés sont des spécialisations d'objets de base existants dans Topic (<step> est par exemple une spécialisation de la balise standard <ul>).
L'objet Task peut alors lui même être spécialisé, pour répondre à un besoin particulier, comme l'illustre par exemple le schéma suivant :
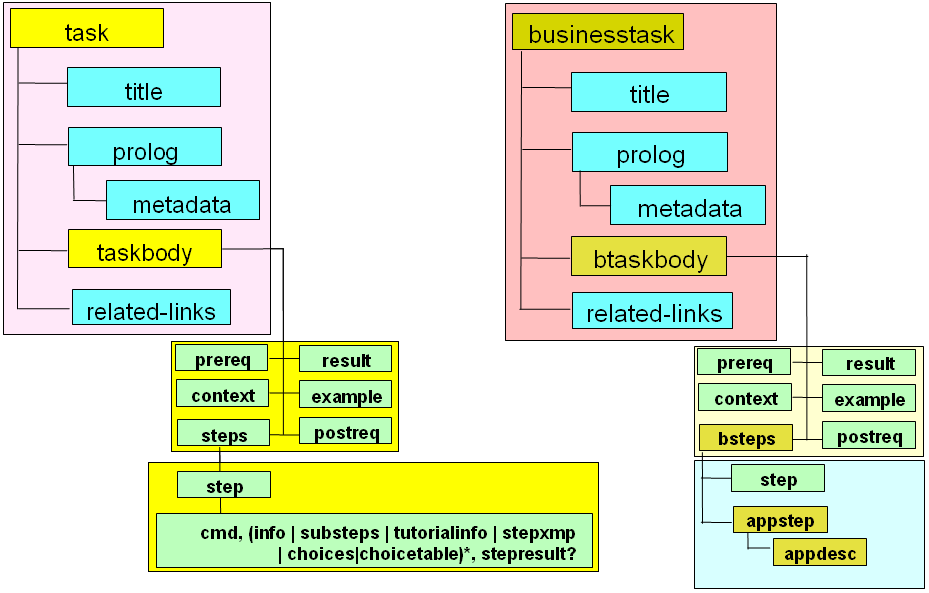
Ces schémas sont extrait de la présentation «Introduction to DITA specialization»
par IBM (2004), disponible sur le site Cover Pages d'Oasis.
Inconvénients
Le standard DITA offre donc les avantages cités précédemment. En revanche il a également ses inconvénients, principalement liés à sa complexité.
En effet la spécification DITA est complexe, donc difficile à appréhender et à bien utiliser pour les raisons suivantes :
le modèle est très générique et très riche : une connaissance approfondie du modèle est nécessaire pour créer du contenu DITA. Cette généricité et cette richesse impose à chaque organisation de définir ses propres règles de rédaction et/ou de spécialiser le modèle pour l'adapter au mieux à ses propres besoins et faciliter le travail du rédacteur technique.
la complexité de la spécification et du concept de spécialisation, qui induit une complexité dans l'implémentation de cette spécialisation et également dans celle du moteur de génération DITA OT (dont la publication standard est "pauvre" et complexe à customiser). De plus la spécialisation a ses limites, étant un mécanisme restrictif basé sur un principe d'héritage.
le standard est très permissif : la notion d'embeded Topic ou encore le mécanisme d'inclusion avec la balise conref par exemple, peuvent conduire à produire un contenu inutilisable et peu maintenable si ils sont mal implémentés.
la rédaction s'effectue dans des éditeurs XML généralement peu ergonomiques, qui plus est avec un modèle complexe tel que DITA. Un CCMS[1] est souvent nécessaire pour permettre de gérer à grande échelle un tel contenu structuré.
Cette complexité fait de DITA un choix coûteux à mettre en œuvre : besoin de compétences et de formation des rédacteurs techniques, besoin de spécialisation du modèle et du moteur de publication, acquisition des logiciels d'édition et de gestion, etc.
Ces inconvénients nuisent probablement à l'adoption de cette norme par le plus grand nombre, notamment les PME ne pouvant ou ne souhaitant pas investir de manière significative pour leur documentation.
Un marché se créé autour de cette problématique et certains éditeurs du marché créé des logiciels pour simplifier DITA aux utilisateurs (par exemple Easy DITA, DITA Storm, Codex, etc.) en proposant des éditeurs WYSIWYG web proche de l'édition bureautique, des fonction collaboratives (écriture collaborative, annotations, révisions) et des modèles DITA simplifiés pour certains.
Un autre inconvénient plus fonctionnel, est que, par essence, DITA produit des documents peu linéaires, une Map étant une agrégation hiérarchisée de fragments de contenus individuels autonomes. Cette caractéristique est typique de l'ensemble des documents DITA que nous avons pu trouver et elle convient particulièrement à certains types de documents tels les manuels d'utilisation ou les documents de référence mais probablement moins à des documents nécessitant plus de rédactionnel et de liant entre les fragments, comme un guide de formation technique.
Quelques exemples de contenus DITA en ligne (HTML, PDF, Web help, Eclipse Help)
Eclipse Help (jsp) : Alfresco
Doc PDF : Swordfish, Guide d'installation plomberie , guide d'installation carte graphique PDFAMD
User guide Oxygen : PDF et WebHelp; user guidePitStop pro
Documentation DITA : Ditainfo

